










✔«Яндекс» открывает библиотеку YaFSDP для обучения больших языковых моделей - «Новости»
Компания «Яндекс» выложила в опенсорс библиотеку YaFSDP, которая ускоряет обучение больших языковых моделей — как собственной разработки, так и сторонних, с открытым исходным кодом. Библиотека дает ускорение до 25% (результат зависит от архитектуры и параметров нейросети). С помощью YaFSDP можно расходовать до 20% меньше ресурсов графических процессоров (GPU), которые требуются для обучения.
В первую очередь библиотека рассчитана на большие языковые модели, хотя подходит и для других нейросетей — например, таких, которые генерируют изображения. Разработчики пишут, что YaFSDP позволяет сократить расходы на оборудование для обучения моделей, что особенно важно для стартапов и, к примеру, научных проектов.
Одна из сложностей в обучении больших языковых моделей — это недостаточная загрузка каналов коммуникации между графическими процессорами. YaFSDP призвана решить эту проблему. Библиотека оптимизирует использование ресурсов GPU на всех этапах обучения: pre-training (предварительное), supervised fine-tuning (с учителем), alignment (выравнивание модели). Благодаря этому YaFSDP задействует ровно столько графической памяти, сколько нужно для обучения, при этом коммуникацию между GPU ничто не замедляет.
Специалисты «Яндекса» разработали YaFSDP в процессе обучения своей генеративной модели YandexGPT 3. Компания сообщает, что уже протестировала библиотеку на сторонних нейросетях с открытым исходным кодом. Например, если бы YaFSDP использовалась применительно к модели LLaMA 2, этап предварительного обучения на 1024 графических процессорах сократился бы с 66 до 53 дней.
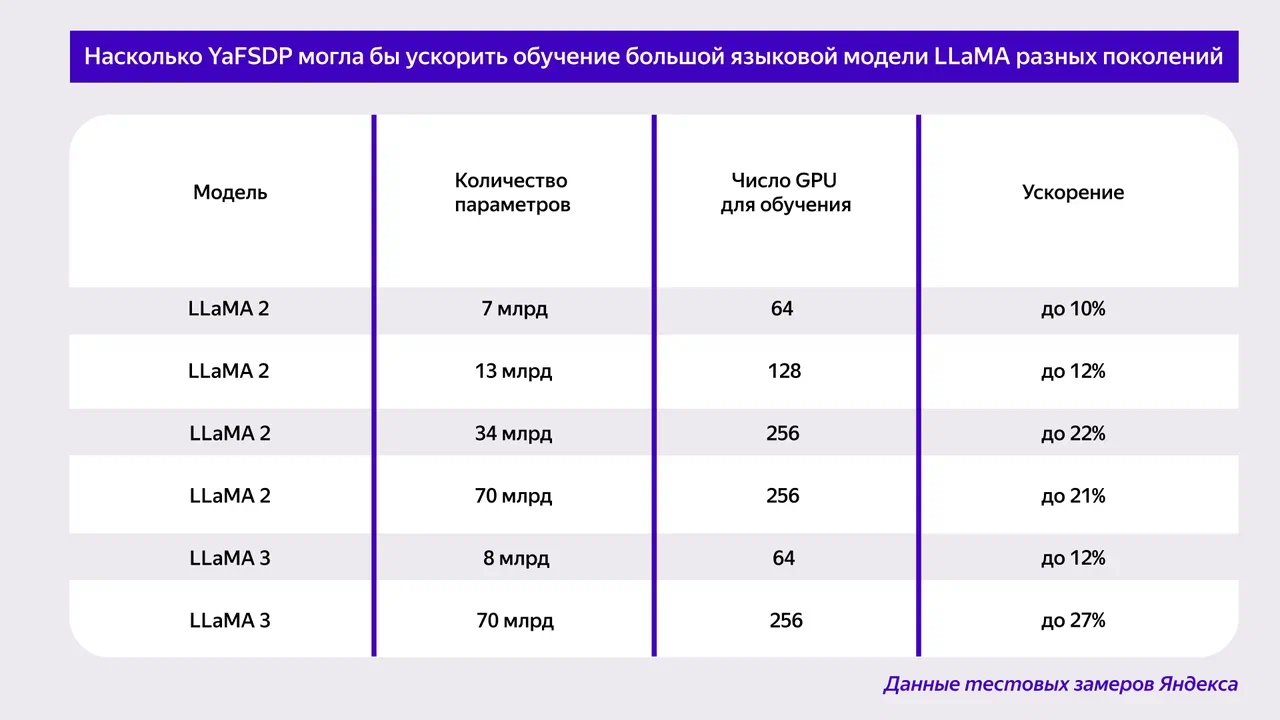
Исходный код YaFSDP уже доступен на GitHub. Посмотреть подробности замеров можно в репозитории GitHub, а почитать про разработку библиотеки — в статье на «Хабре».







