✔Машинное обучение в интернет-рекламе: как и зачем его применяют - «Заработок»
Мы ежедневно сталкиваемся с машинным обучением: строим маршруты, заказываем такси, слушаем музыку, смотрим видео, листаем умную ленту, получаем рекомендации в интернет-магазинах, видим персонализированную рекламу.
Машинное обучение неразрывно связано с нашей жизнью, а сферы его применения постоянно расширяются. В статье я расскажу, как работает машинное обучение, какие задачи решает и для чего применяется в рекламных системах.
Зачем нужно машинное обучение
Когда мы перестали довольствоваться тем, что алгоритмы выдают определенные ответы на вопросы, появилась потребность в машинном обучении.
Давайте представим, что программа должна отличать кошек от собак. Невозможно написать огромную формулу с сотней переменных, чтобы с точностью отличить одно от другого. Как и невозможно показать всех возможных кошек и собак, чтобы заставить алгоритм каждый раз сравнивать объект со всеми предыдущими.
Чтобы решить эту задачу, программа, как и человек, должна уметь находить признаки, на основе которых она сможет отличить одно от другого.
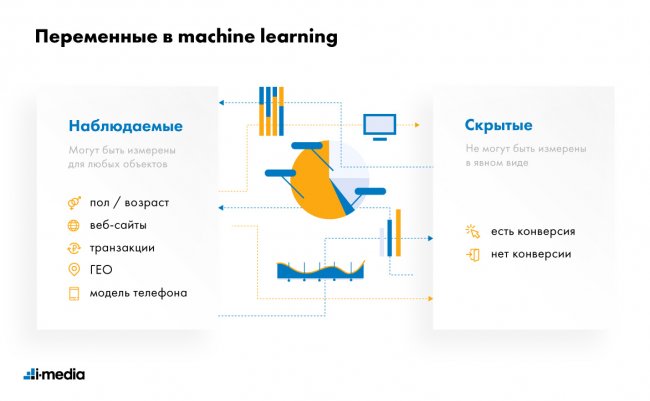
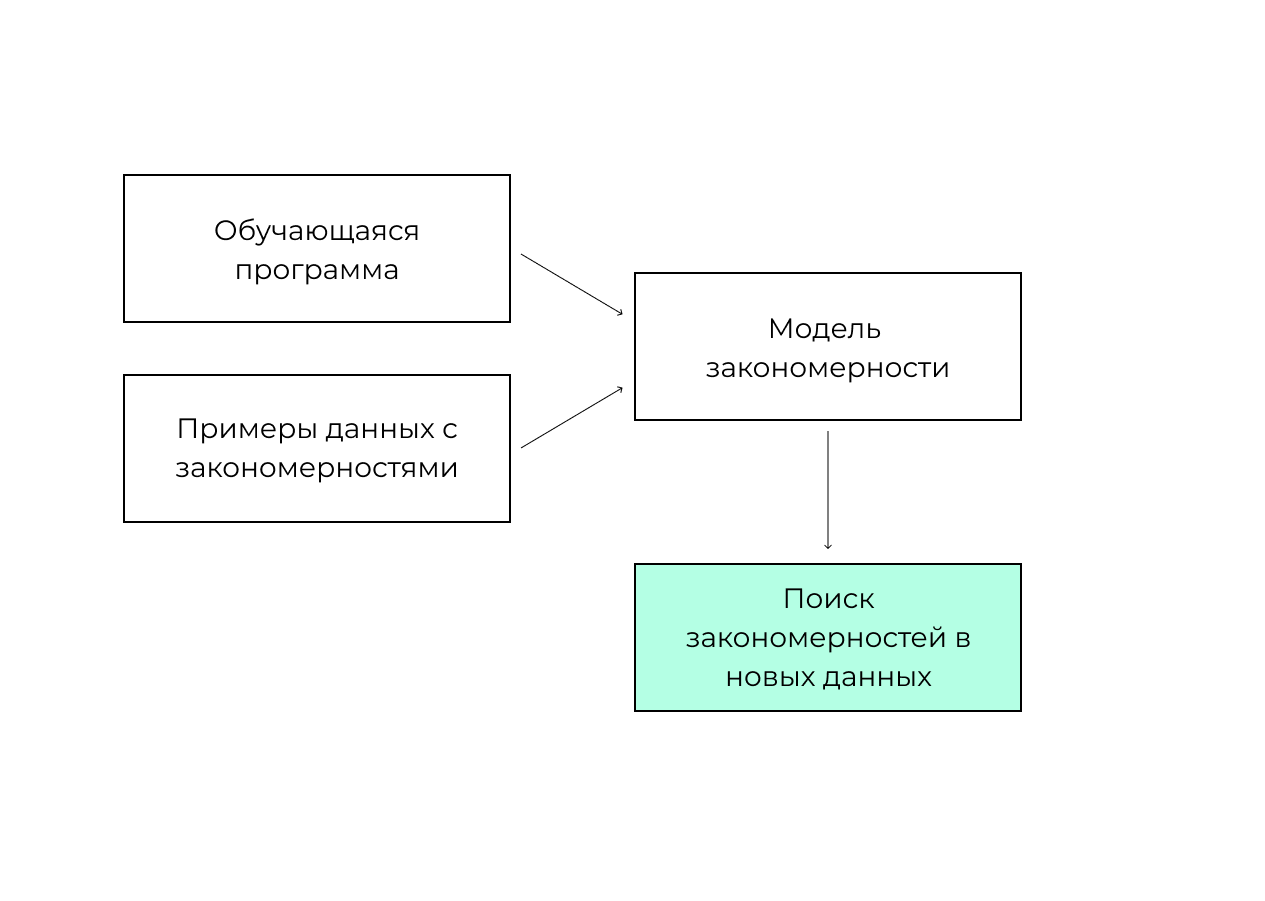
Машинное обучение — это алгоритм, с помощью которого система распознает данные и их закономерности, предсказывает значение на основе обученной модели.
Схематически это можно изобразить так:
Какие задачи решает машинное обучение
Регрессия — предсказание числовых значений в будущем на основании известных данных в прошлом. Пример: прогноз бюджета, вероятность конверсии.
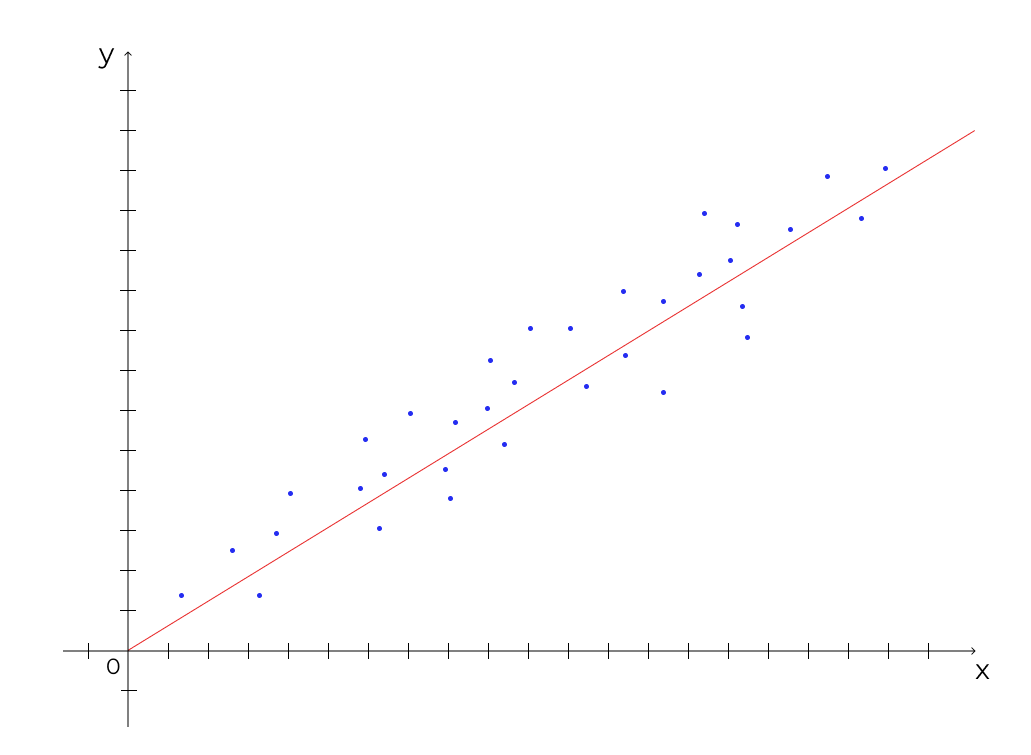
Популярные алгоритмы: линейная и логистическая регрессии, нейронные сети.
Классификация — предсказание, к какому классу относится объект. Пример: распознавание голоса, спам-фильтр.
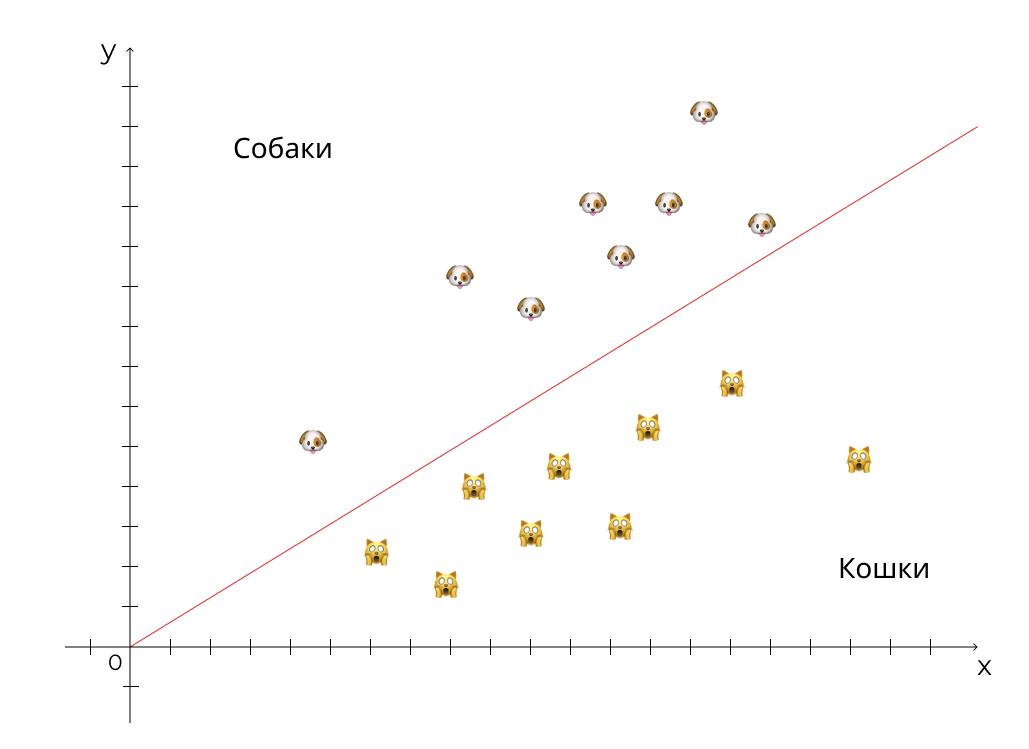
Популярные алгоритмы: деревья решений, логистическая регрессия, k-ближайших соседей, машины опорных векторов.
Кластеризация — разделение объектов на кластеры, непохожие друг на друга, но схожие внутри между собой. Пример: таргетинг по интересам, жанр музыки.
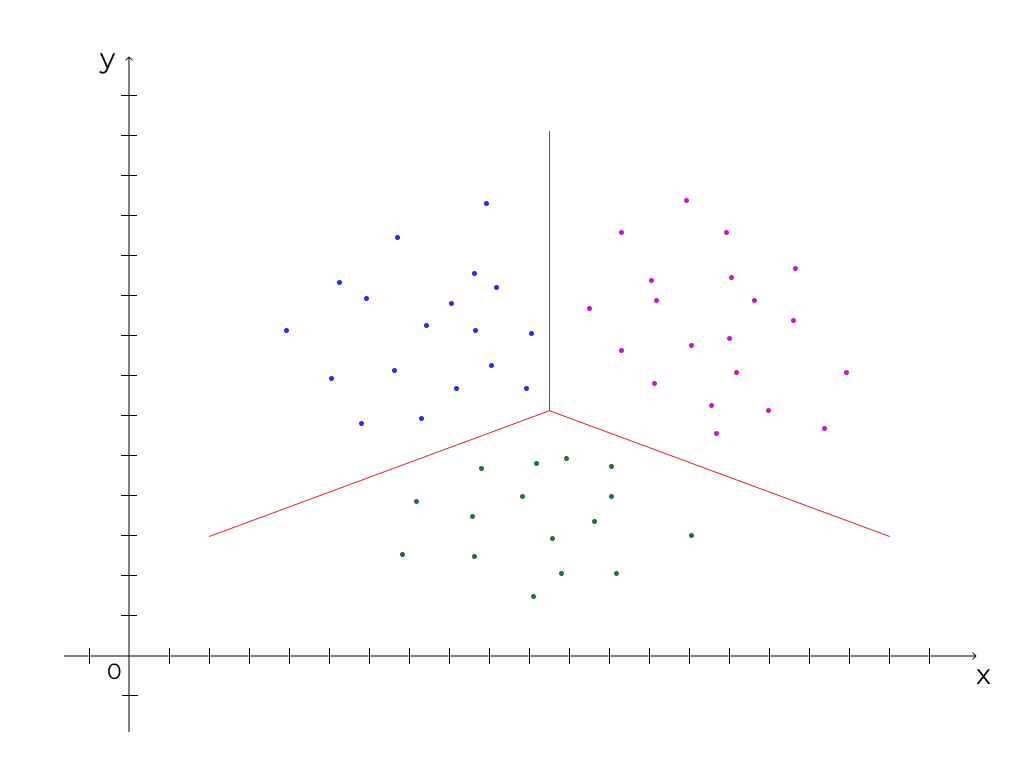
Популярные алгоритмы: метод k-средних, Mean Shift, DBSCAN.
Поиск аномалий — поиск объектов, существенно отличающихся от основной массы. Пример: исправление опечаток, антикапча.

Популярные алгоритмы: k-ближайших соседей, локальный уровень выброса, метод опорных векторов, Байесовские сети.
Поиск ассоциативных правил — поиск закономерностей в наборе данных. Пример: динамические ремаркетинг, рекомендации в корзине.
Популярные алгоритмы: Apriori, Euclat, FP-growth.
Как мы видим, одну и ту же задачу почти всегда можно решить разными способами.
Banner
Основные виды машинного обучения
С учителем. Система обучается на заранее размеченных данных, между которыми есть определенная зависимость.
Пример:
Размер
Форма ушей
Животное
маленький
торчит
кошка
маленький
торчит
кошка
маленький
торчит
кошка
большой
не торчит
кошка
большой
торчит
собака
большой
торчит
собака
большой
торчит
собака
маленький
не торчит
собака
Размер и форма являются признаками наших данных, а животное — значением. В таблице видна зависимость между размером и типом животного. Задача алгоритма — найти эту связь и на основе обученной модели предсказать новое животное.
Без учителя. Та же самая классификация, но без заранее известных ответов — машина самостоятельно находит похожие объекты и группирует их в кластеры. Недавно мой iPhone создал видео, в котором собрал все фотографии с животными. Я не говорил ему, где человек, а где животное — он сам отделил одно от другого.
Обучение с подкреплением. Система учится, взаимодействуя со средой. Применяется в автопилотах, играх, торговле акциями. В этом методе система учится не на заранее размеченных данных, а на сигналах, которые либо поощряют ее, либо наказывают — в зависимости от принятого решения.
Примеры сигналов: если Марио идет вправо и собирает монеты — хорошо, если падает в яму или врезается в гриб — плохо.
Ансамбли. Когда для лучшего прогнозирования не подходит ни один алгоритм, используют сразу несколько моделей. Крупные компании применяют чаще всего именно ансамбли. Часто используемые типы:
Стекинг. Результаты работы нескольких алгоритмов показывают последнему алгоритму для принятия решения.
Бэггинг. Алгоритм обучают много раз на отдельных выборках, после чего данные усредняют.
Бустинг. Как и в бэггинге, алгоритм обучают много раз на отдельных выборках. Но в каждую новую выборку попадают данные из выборки, на которых предыдущий алгоритм ошибся — таким образом алгоритм доучивается.
Искусственные нейросети. Сети, которые состоят из нейронов, связанных между собой. Нейроны на входе получают сигналы, преобразуют их и на выходе отдают число, которое при определенном условии активирует связь со следующим нейроном. Каждая связь между нейронами имеет определенный вес. После вычисления весов связей между всеми нейронами, сеть выдает правильный или неправильный ответ. Если ответ неправильный, сеть самостоятельно корректирует значимость каждой связи до тех пор, пока не научится выдавать правильный результат.
Советую посмотреть по теме видео, поскольку понять из одного определения, что такое нейронные сети, вряд ли возможно.
Как работают алгоритмы
Мы рассмотрим один из наиболее популярных алгоритмов машинного обучения — «деревья решений». Он лежит в основе более сложного алгоритма градиентного бустинга, который используется Яндексом для решения разных задач:
- построения рекомендаций музыки и покупок;
- распознавания голоса;
- предсказания погоды;
- ранжирования выдачи.
Библиотека Catboost выложена в открытый доступ на GitHub и любой желающий может попробовать применить ее на своих данных.
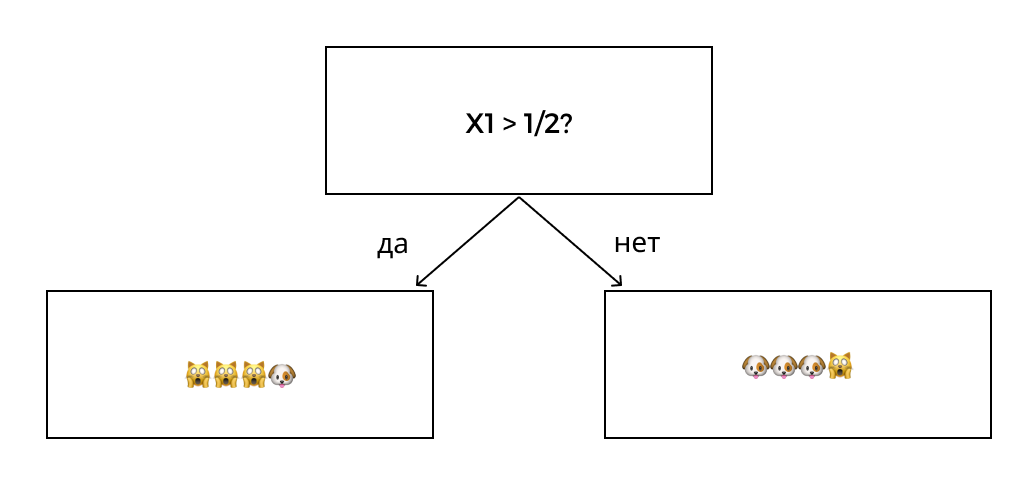
Мы неосознанно используем деревья решений, когда принимаем какое-либо решение. Например, так выглядит дерево, когда мы смотрим в окно и думаем, идти ли на улицу или лучше остаться дома:

Аналогичным образом работает алгоритм машинного обучения. Система последовательно задает вопросы, которые удовлетворяют и не удовлетворяют условию, и делит данные на группы. Каждый последующий вопрос снижает уровень неопределенности исходных данных до тех пор, пока не будет достигнута определенность.
Чтобы снизить уровень неопределенности, мы должны задать вопрос, который приблизит нас к правильному ответу. Когда мы собираемся на улицу, мы не спрашиваем, есть ли за окном воробьи — этот вопрос не снизит уровень неопределенности и не поможет принять правильное решение.
Но как алгоритм понимает, какой нужно задать вопрос? Вернемся к нашему примеру с кошками и собаками, где X1 и X2 являются признаками наших данных, а Y — значением.
X1
X2
Y
маленький
торчит
кошка
маленький
торчит
кошка
маленький
торчит
кошка
большой
не торчит
кошка
большой
торчит
собака
большой
торчит
собака
большой
торчит
собака
маленький
не торчит
собака
Задача алгоритма — найти зависимость между признаками и значениями, чтобы в будущем на основании одних только признаков уметь с наибольшей вероятностью определять значение. Так как алгоритм не работает с номинативными переменными, переведем наши значения в числовые и получим следующую таблицу:
X1
X2
Y
1
0
?
1
0
?
1
0
?
0
1
?
0
0
?
0
0
?
0
0
?
1
1
?
В наших данных по-прежнему есть четыре кошки и четыре собаки, а также признаки, которые их характеризуют. Вероятность того, что перед нами появится кошка или собака, ?, неопределенность, или энтропия, максимальная и равна 1. Если бы в наших данных все признаки принадлежали только одному классу, например, собаке, неопределенности бы не было, энтропия равнялась нулю, алгоритм со 100%-й вероятностью нам сказал, что следующим животным будет собака.
Какой вопрос нужно задать алгоритму, чтобы снизить уровень неопределенности? У нас есть два признака, по которым можно разбить наши данные. Давайте посмотрим, что будет, если разбить данные по признаку X1. Для этого зададим вопрос:
Когда мы разбили данные по признаку X1, уровень неопределенности стал ниже, но некоторая неопределенность все еще присутствует.
Разобьем данные по признаку X2:

Определенность в наших данных так не появилась, энтропия и там, и там осталась равна единице. Вывод — нужно делать сплит по признаку X1. На следующей ветке дерева алгоритм задает новый вопрос. Что, если:
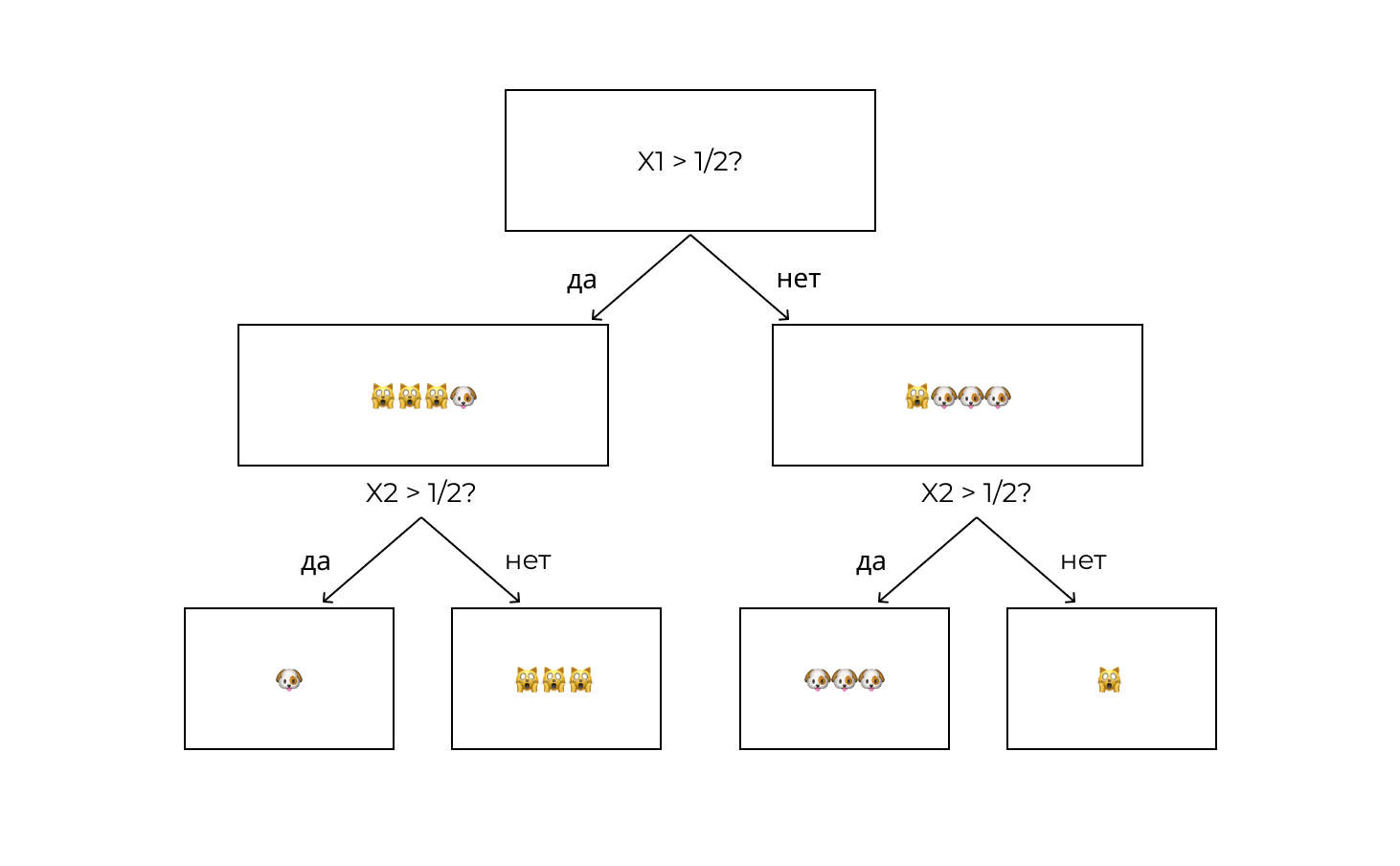
Таким образом, последовательно перебирая признаки с целью снижения неопределенности, алгоритм обучается и достигает полной определенности.
Чтобы понять, как считается энтропия, информационный выигрыш и другие математические основы машинного обучения, смотрите курс на Stepik.
Аналогичным образом алгоритм может учитывать сотни параметров. Главная задача в обучении машины — научить ее определять данные с наименьшим количеством ошибок при наименьшем количестве действий. Это регулируется с помощью определения глубины дерева. Если дать дереву слишком сильно разрастись, оно может:
- переобучиться — и тогда будет работать верно только на определенных данных;
- недообучиться — тогда вероятность ошибки будет слишком высокой.
Как это выглядит, смотрите на рисунках ниже:
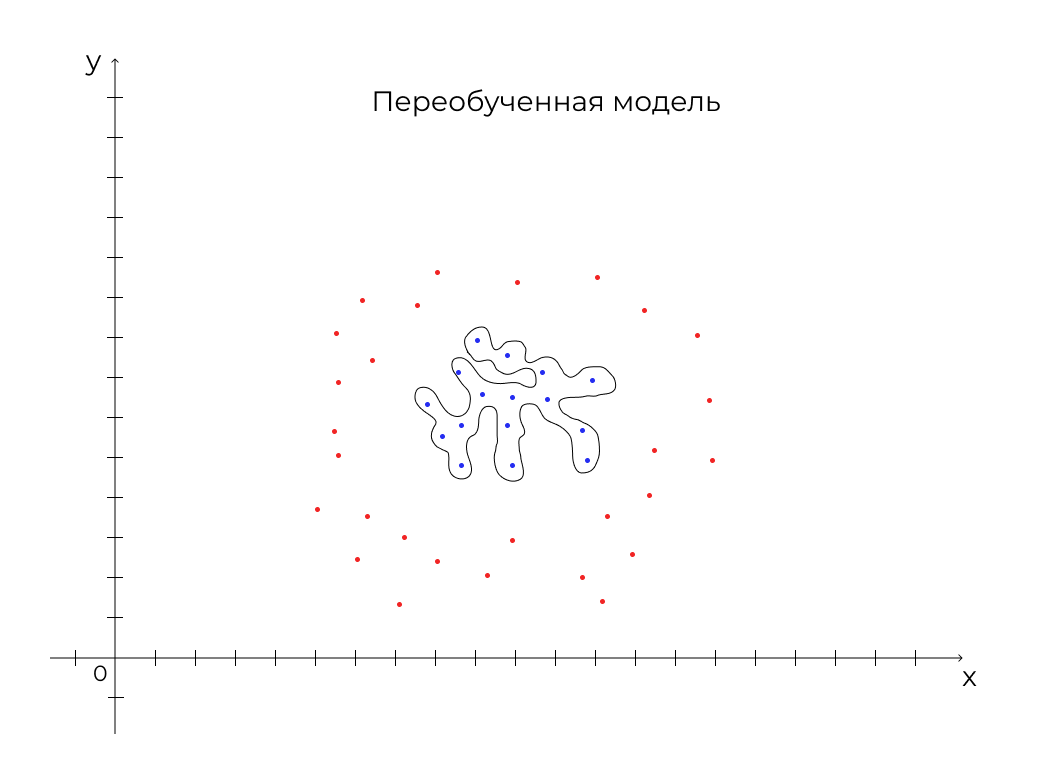
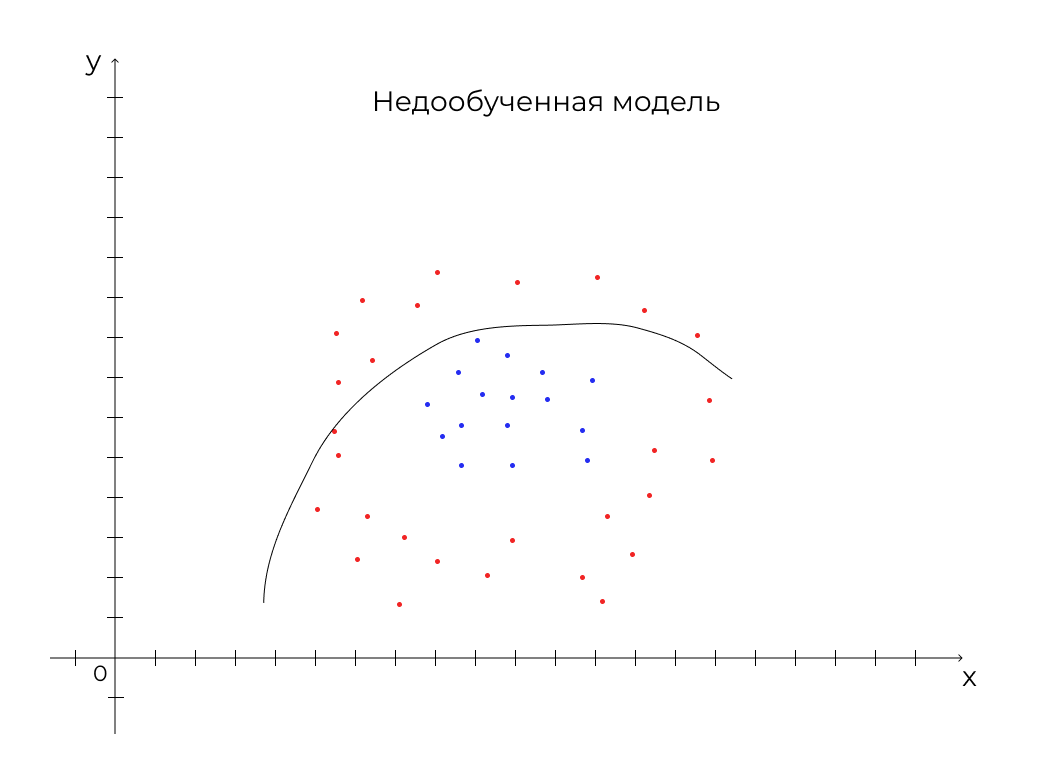

Мы разобрали принцип работы одного из алгоритмов машинного обучения. Выяснили, что натравить машинное обучение на имеющиеся данные — мало, нужно подобрать модель, которая будет иметь баланс между недообучением и переобучением. Теперь рассмотрим, как машинное обучение применяется в рекламных системах.
Машинное обучение в маркетинге
Традиционный маркетинг имеет ограниченные представления о поведении потенциальных покупателей. В интернете же системы размещения рекламы владеют большим объемом информации о пользователях и их поведении. Эта информация и методы машинного обучения помогают достигать лучших показателей эффективности рекламы.
В качестве примеров я приведу 10 способов применения машинного обучения в рекламных системах, а вы попробуйте добавить другие в комментариях.
Поисковые подсказки
Мы сталкиваемся с машинным обучением, когда хотим найти что-то в интернете. Яндекс умеет не только предсказывать ваш запрос, помогая ввести его с помощью поисковых подсказок, но и предзагружать выдачу еще до того, как вы нажмете кнопку «найти».
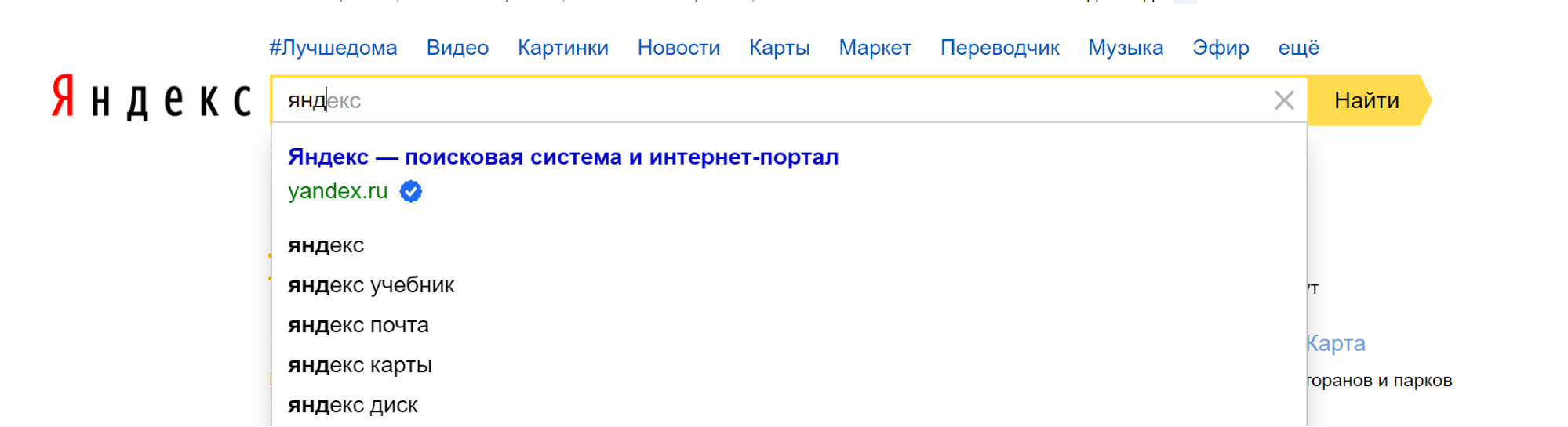
Для решения этой задачи разработан классификатор, который определяет, в каких случаях можно предзагружать выдачу, а в каких — нельзя. Увеличение скорости ответа способствовало тому, что люди стали чаще возвращаться в поисковик. Рекомендую интересную статью от Яндекса о поисковых подсказках на Habr.
Распознавание голоса
Если вы не вводите запрос руками, а произносите голосом, машинное обучение помогает распознавать речь. Машина не понимает слова, и всё, что вы говорите, — это сигналы, а одно и то же слово, произнесенное разными людьми, имеет различные входные сигналы.
Система раскладывает слова на микрочастицы, фонемы. Фонемы — на еще меньшие частицы, сеноны. Также она рассчитывает вероятность перехода одной частицы в другую, и наиболее вероятный вариант перехода возвращает результат распознавания речи. Захватывающая статья об этом — тоже на Habr.

Интеллектуальное назначение ставок
Автоматические стратегии, основанные на машинном обучении, способны значительно повысить эффективность рекламы. Они умеют:
- с высокой точностью предсказывать вероятность совершения конверсии;
- удерживать стоимость конверсии или рентабельность инвестиций на заданном значении;
- получать максимум кликов по определенной цене;
- увеличивать ценность конверсии при ограниченном бюджете;
- получать максимальную видимость объявлений.
Благодаря этому высока вероятность, что объявление будет доставлено определенному пользователю в нужное время.
Перед тем как показать нам рекламу, стратегии Google учитывают следующие сигналы:
- устройство;
- местоположение;
- намерение, связанное с местоположением (если пользователь находится в одном городе, а ищет запрос в другом, то он всё равно сможет увидеть объявление);
- день недели и время суток;
- входит ли пользователь в список ремаркетинга и как давно добавлен;
- особенности объявления;
- язык интерфейса;
- браузер пользователя;
- операционную систему;
- поисковый запрос;
- сайт поискового партнера;
- сайт в Контекстно-медийной сети;
- поведение пользователя на сайте в Контекстно-медийной сети;
- атрибуты рекламируемого товара;
- рейтинг мобильных приложений;
- накопленную статистику.
В ближайшее время автоматические стратегии смогут учитывать стоимость товара по сравнению с товарами конкурентов, а также сезонность.
Недавно я проводил собеседование и удивился, когда соискатель сказал, что не использует автоматические стратегии — он им не доверяет и предпочитает контролировать ставки самостоятельно. Интересно, как он учитывает все эти сигналы в момент аукциона вручную?
Чтобы стратегии работали корректно, у алгоритма должно быть достаточно данных для обучения. Для подключения Целевой цены конверсии Google рекомендую иметь 30 конверсий, рентабельность инвестиций — 50.
Автотаргетинг
На основе содержания сайта и объявления система определяет, когда показать объявление. Чтобы алгоритмы умели это делать, асессоры вручную размечают огромный объем объявлений по шкале, которая отражает, насколько хорошо они соответствуют поисковому запросу и сайту — это и есть то самое обучение с учителем.
Тем, кто хочет подробнее в этом разобраться, советую интересное видео, в котором руководитель группы релевантности рекламы в Яндексе объясняет, как работает автотаргетинг.
У меня этот инструмент хорошо работал в доставке суши. Когда вся семантика уже была проработана вручную, мы получили дополнительные заказы за счет автоматически подобранных низкочастотных запросов.
К похожим инструментам автотаргетинга относятся:
- дополнительные релевантные фразы и синонимы — подбирают запросы, похожие на ключевые слова;
- динамические поисковые объявления — здесь система создает объявление и подбирает семантику на основе сайта или фида.
Адаптивные поисковые объявления
Позволяют показывать более релевантные и полезные объявления. Рекламодатели могут добавить до 15 заголовков и до 4 описаний, система тестирует различные комбинации и находит наиболее эффективную.
Модерация
Прежде чем объявление увидит пользователь, оно должно пройти проверку модерацией на соответствие требованиям. Тут учитываются опечатки, соответствие законодательству, этические нормы, проверяются посадочные страницы. Входящие данные автоматически проверяет около 50 фильтров. Если результат автоматической проверки неоднозначен, идет ручная проверка.
Иногда модерация обходится слишком строго, мои объявления с массажерами отклоняют по ошибке несколько раз в неделю.
Прогноз бюджета
Оценить рекламный бюджет позволяет прогноз. Система рассчитывает расходы на основе статистики показов и кликов, сезонности и ставок в каждом регионе. Как правило, опыт позволяет гораздо точнее оценить результаты будущей кампании, чем машинное обучение. Вероятно, данные, которыми оно предлагает, слишком усредненные, в то время как человек заранее знает, какой стратегии будет придерживаться и сколько готов платить за клик.
Скликивание
Еще один способ применения машинного обучения в рекламных системах — поиск аномалий трафика. Система Директа фильтрует три основных типа некачественного трафика:
- Склик — накрутка кликов, чтобы потратить бюджет рекламодателя. Доля такого типа трафика составляет от 10 до 30%. Склики могут производить как роботы, так и люди.
- Скрутка — накручивание показов, чтобы испортить CTR рекламодателя.
- Повторные и случайные клики — рекламодатель платит за случайные клики.
Чтобы отсечь недоброкачественный трафик, система также анализирует трафик по более чем 250 параметрам: время суток, сезон, география, события до клика, паттерны поведения. Аномальное поведение распознается роботами и фильтрует такой трафик.
Я и сам сталкивался с ситуациями, когда площадка возвращала значительную часть средств за скликивание в РСЯ.
Умная лента и ранжирование
Еще один пример, когда рекламная система решила взять подбор таргетинга на себя. В Яндекс.Дзене рекламодатель может выбирать только геотаргетинг, возраст и устройство. Далее на основе поведения пользователей система сама выбирает, кому показать статью.
Учитываются поисковые запросы, история браузера, подписки, клики, лайки, дизлайки, время взаимодействия. Без машинного обучения создать индивидуальную ленту для каждого пользователя невозможно, алгоритм ранжирует миллионы документов для миллионов пользователей и формирует ленту всего за 100–200 мс. Свежая статья о том, как это работает, вышла в блоге Яндекса на Habr.
![]()
Поиск
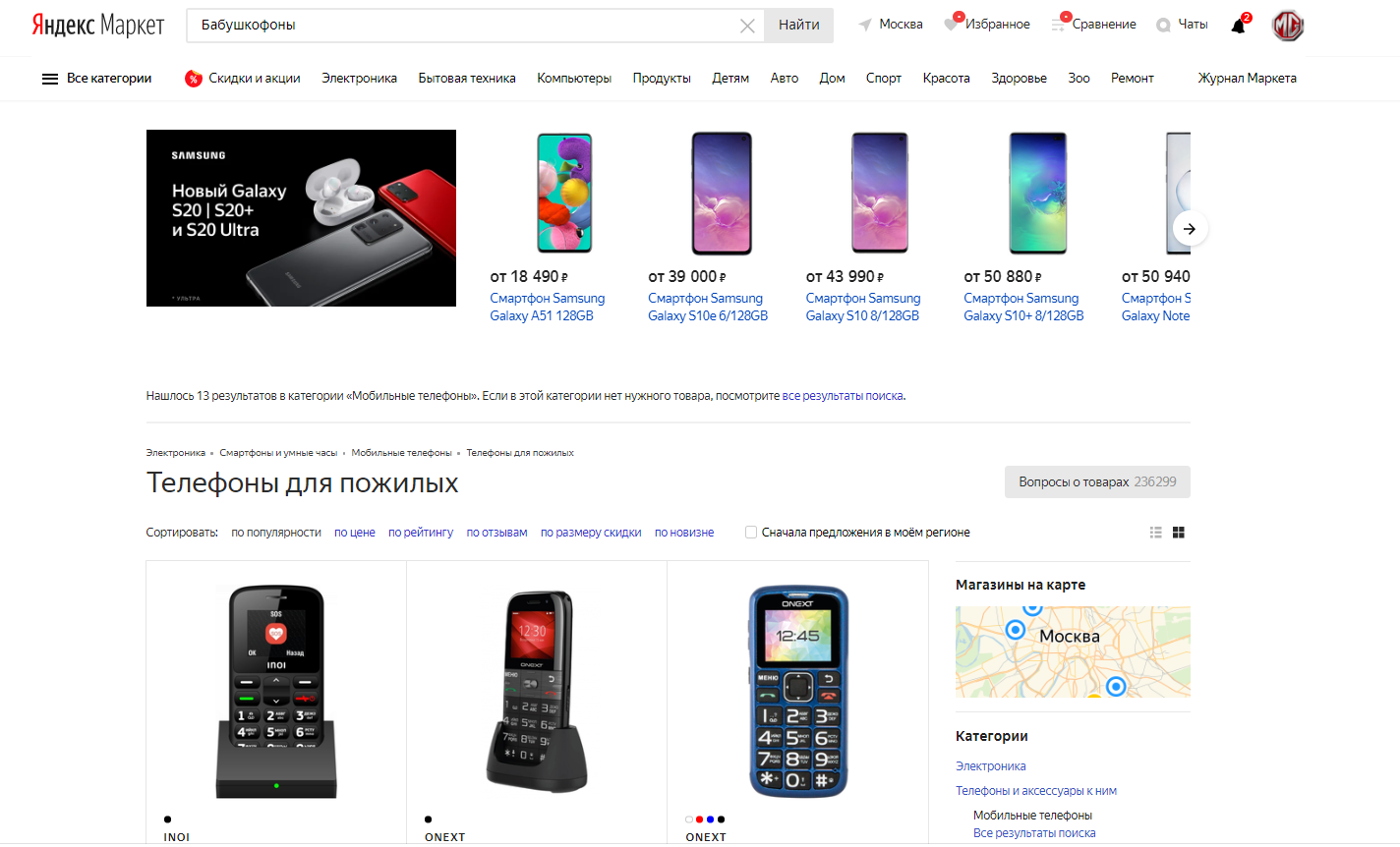
Рассмотрим пример работы поиска в Яндекс.Маркете. Система умеет ранжировать товары по соответствию описания карточки поисковому запросу и в зависимости от того, как пользователи кликают на найденный товар. Так, на основе данных всего поиска система научилась понимать, что бабушкофон — это кнопочный телефон.
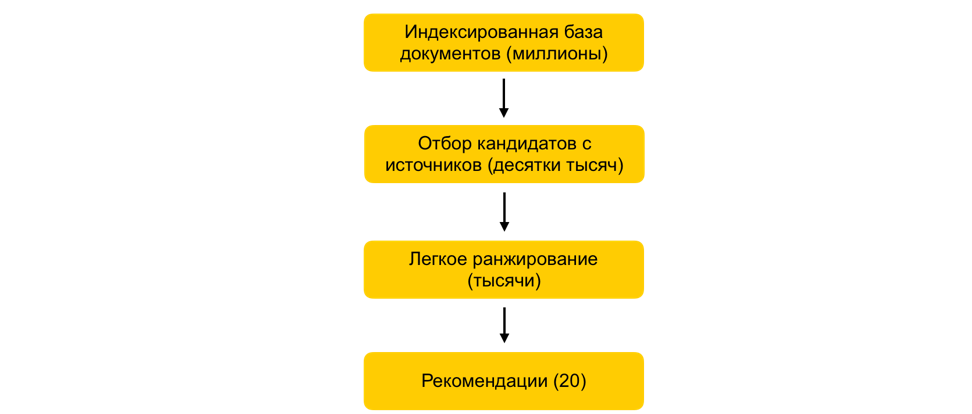
Подробнее о методах машинного обучения в Яндекс.Маркете смотрите в этой лекции.
Заключение
Без машинного обучения не функционирует ни одна рекламная система. Оно значительно увеличивает эффективность онлайн-рекламы, делает системы удобными и полезными для пользователей, облегчает работу рекламодателям, помогая решить сложные и рутинные задачи, и одновременно учитывает множество факторов для принятия решения, которые не может учесть человек.
Тем, кто всерьез заинтересовался темой, рекомендую изучить материалы в этой подборке:
- Эксперимент в Яндексе. Как идентифицировать взломщика с помощью машинного обучения
- Распознавание речи от Яндекса. Под капотом у Yandex.SpeechKit
- Ранжирование в Яндексе: как поставить машинное обучение на поток (пост #2)
- Машинное обучение и анализ данных. Лекция для Малого ШАДа Яндекса
- Яндекс открывает технологию машинного обучения CatBoost
- Поисковые подсказки
- Матрикснет
- CatBoost — новый метод машинного обучения от Яндекса
- Ранжирование и машинное обучение
- Введение в Data Science и машинное обучение
- Что такое машинное обучение и наука о данных
- Что такое машинное обучение и примеры его использования в Яндексе
- Ансамблевые методы: бэггинг, бустинг и стекинг
- Машинное обучение для людей. Разбираемся простыми словами